
The Tangle: an Illustrated Introduction
Part 3
Last week, we learned about the unweighted random walk, and today we will learn about its more advanced cousin: the weighted random walk.
Let's begin with some motivation for studying it. One of the things we want our tip selection algorithm to do is avoid lazy tips. A lazy tip is one that approves old transactions rather than recent ones. It is lazy because it does not bother keeping up to date with the newest state of the Tangle and only broadcasts its own transactions based on old data. This does not help the network, since no new transactions are confirmed.
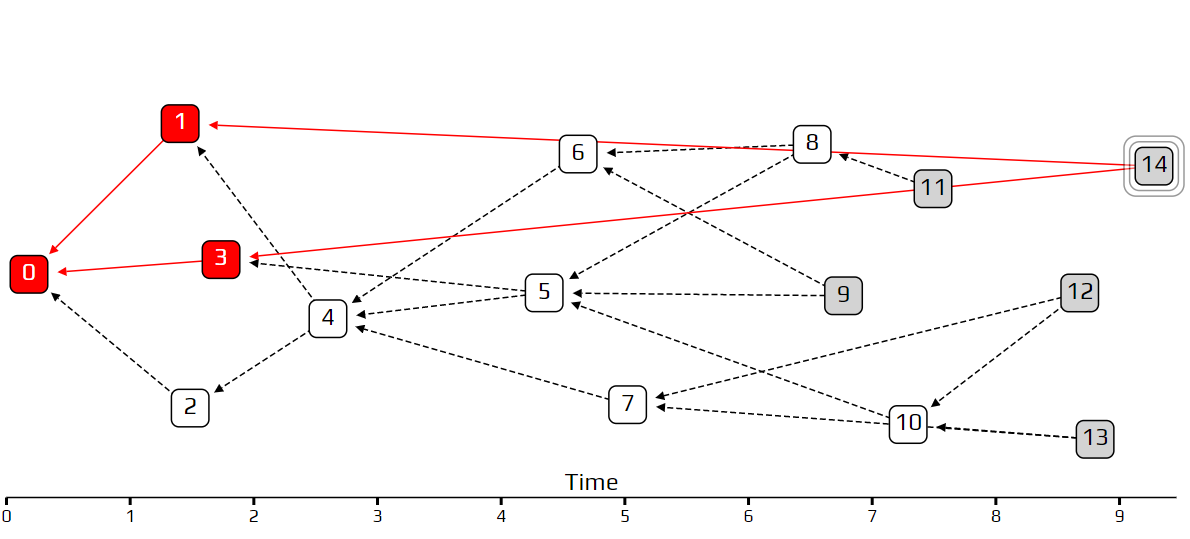
In the example above, transaction 14 is a lazy tip, which approves some very old transactions. If we use the uniform random tip selection algorithm, transaction 14 is just as likely to get approved as any other, so it is not being penalized at all. Using the unweighted walk, this bad behavior is even encouraged, at least in this particular example.
How can we deal with this problem? One thing we cannot do is force participants to only approve recent transactions since that would clash with the idea of decentralization. Transactions can approve by whomever they please. We also don’t have a reliable way of telling exactly when each transaction came in, so we cannot enforce such a rule. Our solution is to construct our system with built-in incentives against such behavior so that lazy tips will be unlikely to get approved by anyone.
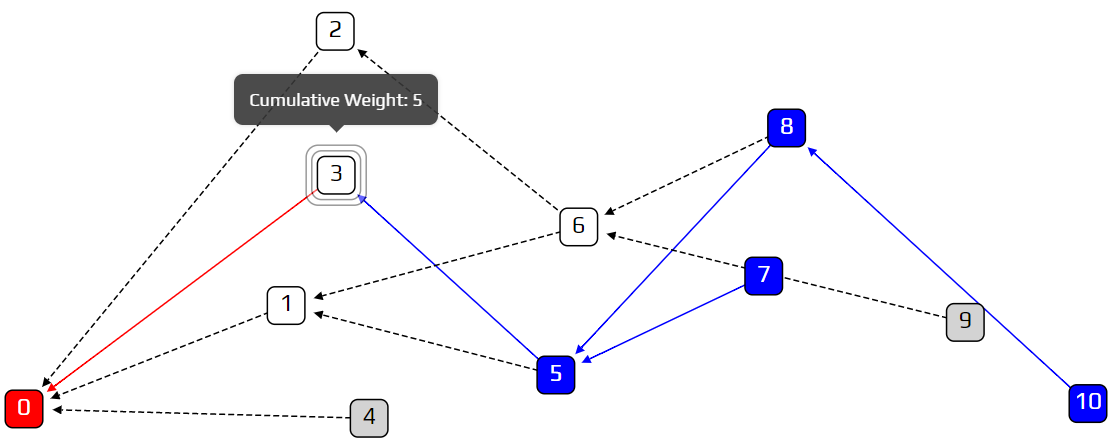
Our strategy will be to bias our random walk, so we are less likely to choose lazy tips. We will use the term cumulative weight to denote how important a transaction is. We are more likely to walk towards a heavy transaction than a light one. The definition of cumulative weight is very simple: we count how many approvers a transaction has, and add one. We count both direct and indirect approvers. In the example below, transaction 3 has a cumulative weight of five, because it has four transactions that approve it (5 directly; 7, 8, and 10 indirectly).

Why does this work? Let’s have a look at another lazy tip situation. In the example below, transaction 16 is a lazy tip. In order for 16 to get approved, the random walker must reach transaction 7, and then choose transaction 16 over transaction 9. But this is unlikely to happen, because transaction 16 has a cumulative weight of 1, and transaction 9 has a cumulative weight of 7! This is an effective way of discouraging lazy behavior.
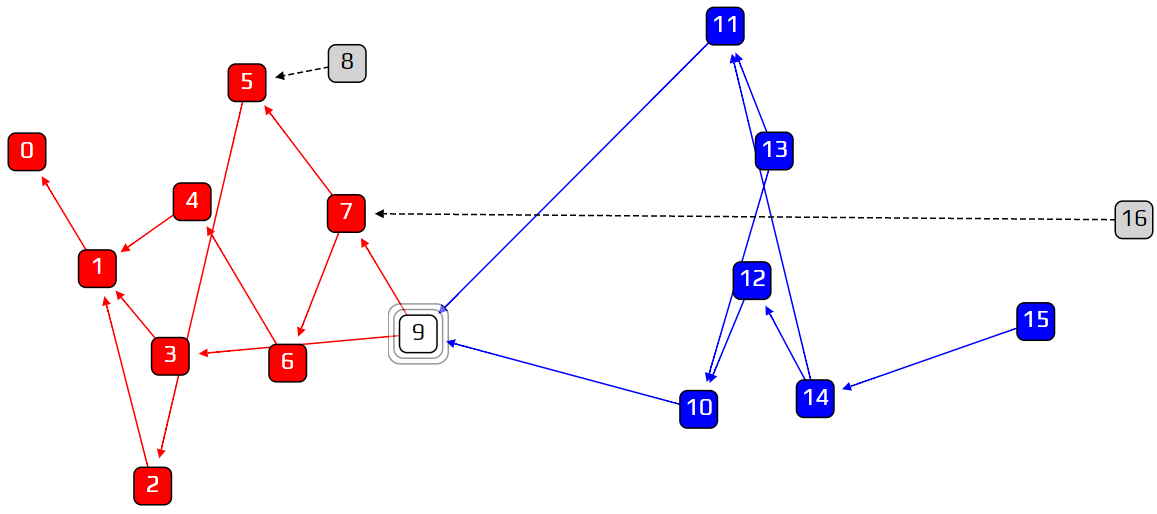
At this point we might ask: do we need randomness at all? We can invent the super-weighted random walk, where at each junction we choose the heaviest transaction, with no probabilities involved. We will then get something like this:
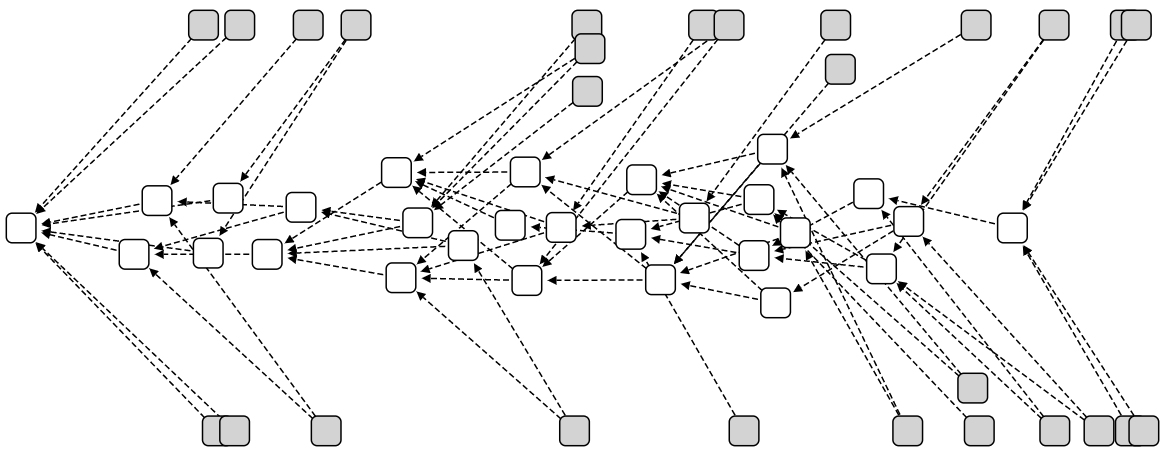
The gray squares are tips, with zero approvers. While it is normal to have some tips on the right end of the diagram, it is a problem to see so many of them spread out across the timeline. These tips are transactions that are left behind, and will never be approved. This is the downside to biasing our walk too much: if we insist on choosing only the heaviest transaction at any given point, a large percentage of the tips will never get approved. We are left with only a central corridor of approved transactions, and forgotten tips on the sidelines.
We need a method to define how likely we are to walk toward any particular approver at a given junction. The exact formula we choose is not important, as long as we give some bias to heavier transactions, and have a parameter to control how strong this bias is. This introduces our new parameterα, which sets how important a transaction’s cumulative weight is. Its exact definition can be found in the white paper, and if there is demand I might write a future post giving some more details on it.
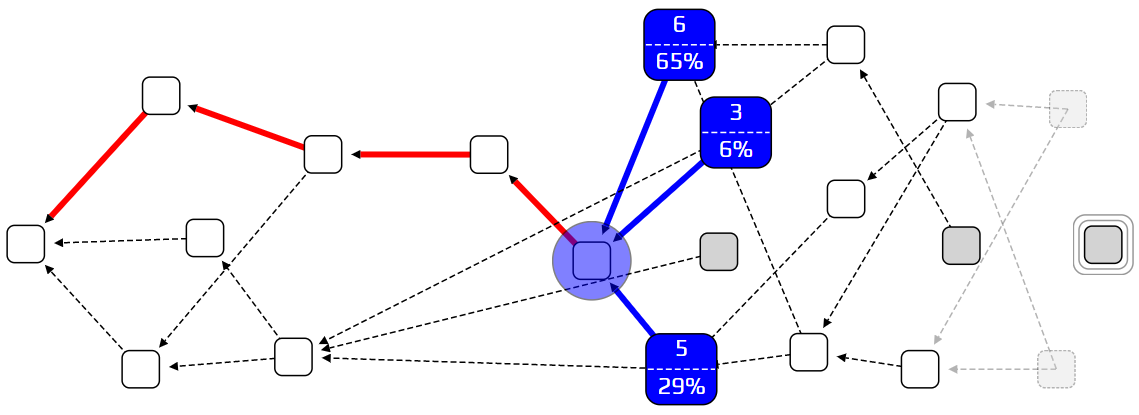
If we setαto zero, we go back to the unweighted walk. If we setαto be very high, we get the super-weighted walk. In between, we can find a good balance between punishing lazy behavior and not leaving too many tips behind. Determining an ideal value for α is an important research topic in IOTA.
This method of setting a rule for deciding the probability of each step in a random walk is called a Markov Chain Monte Carlo technique, or MCMC. In a Markov chain, each step does not depend on the previous one but follows a rule that is decided in advance.
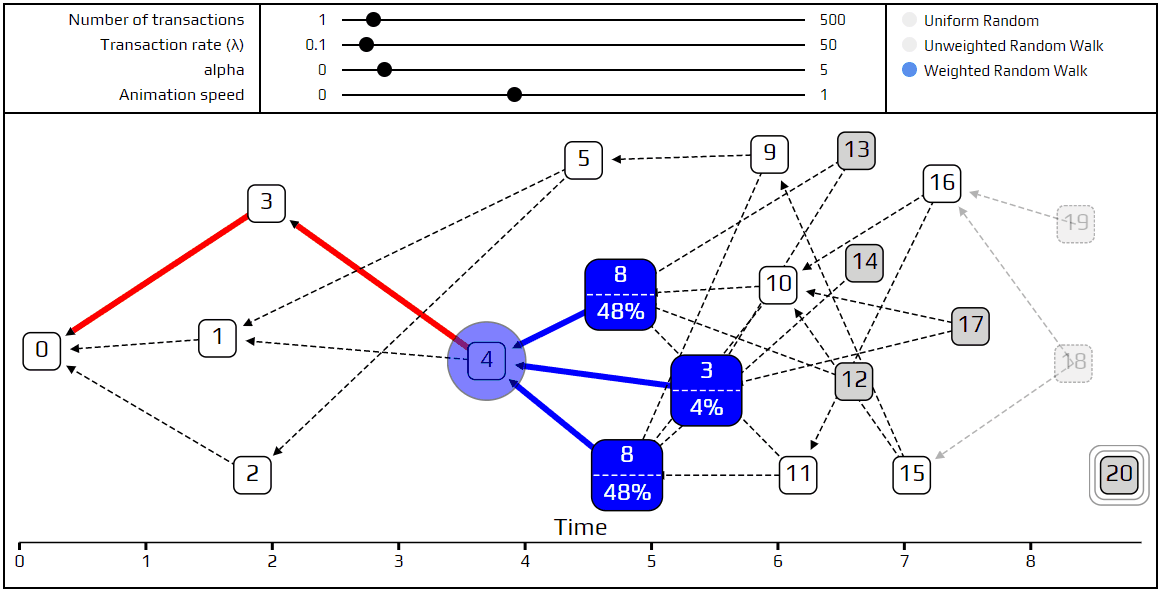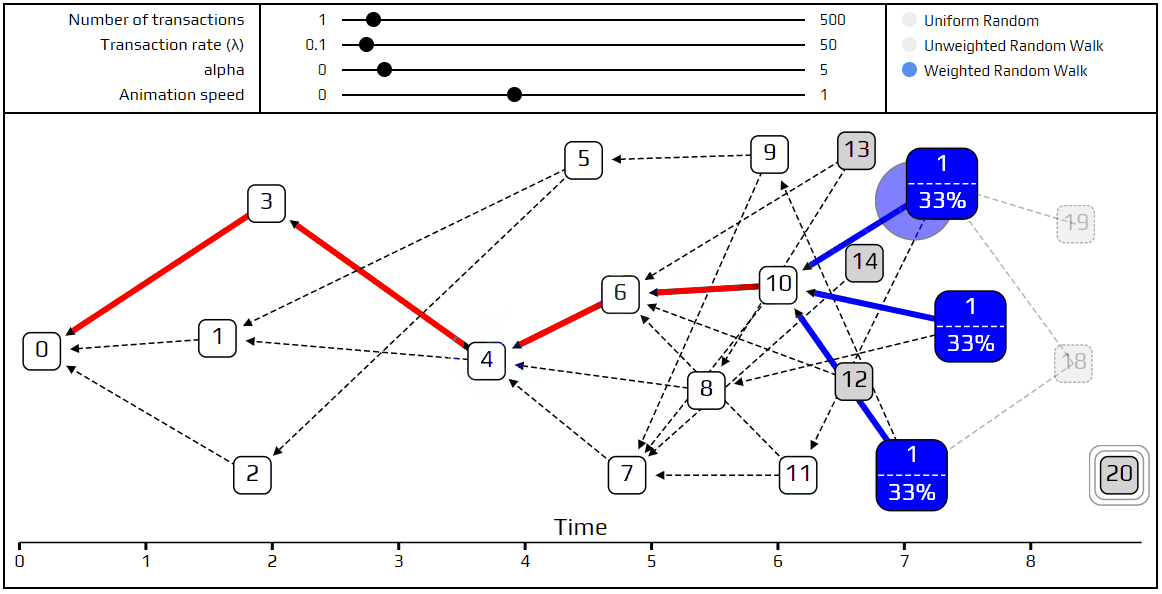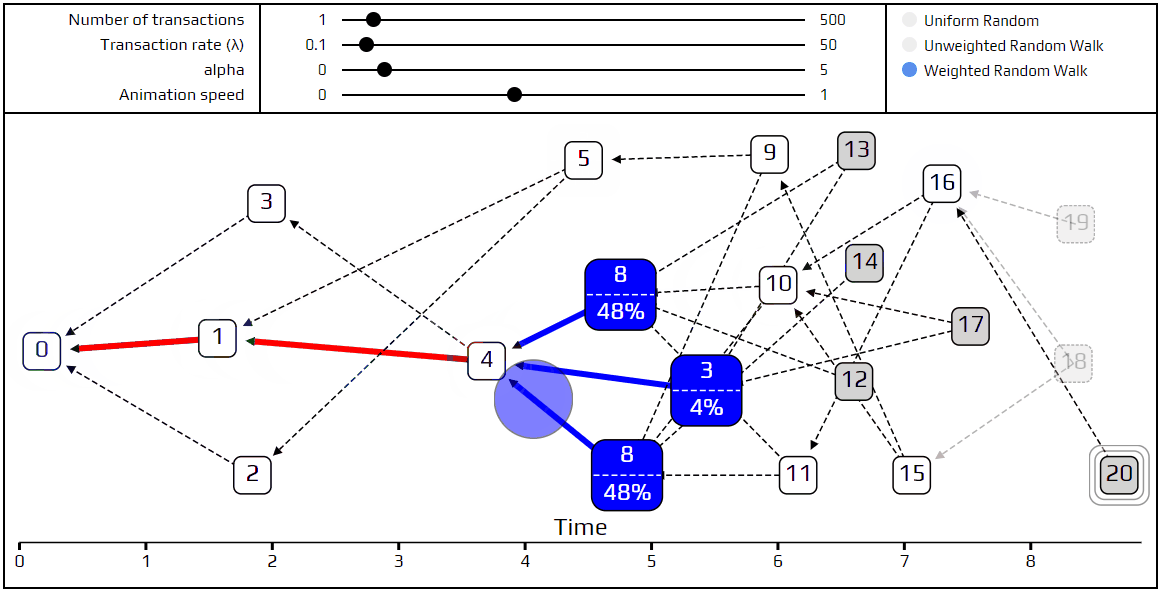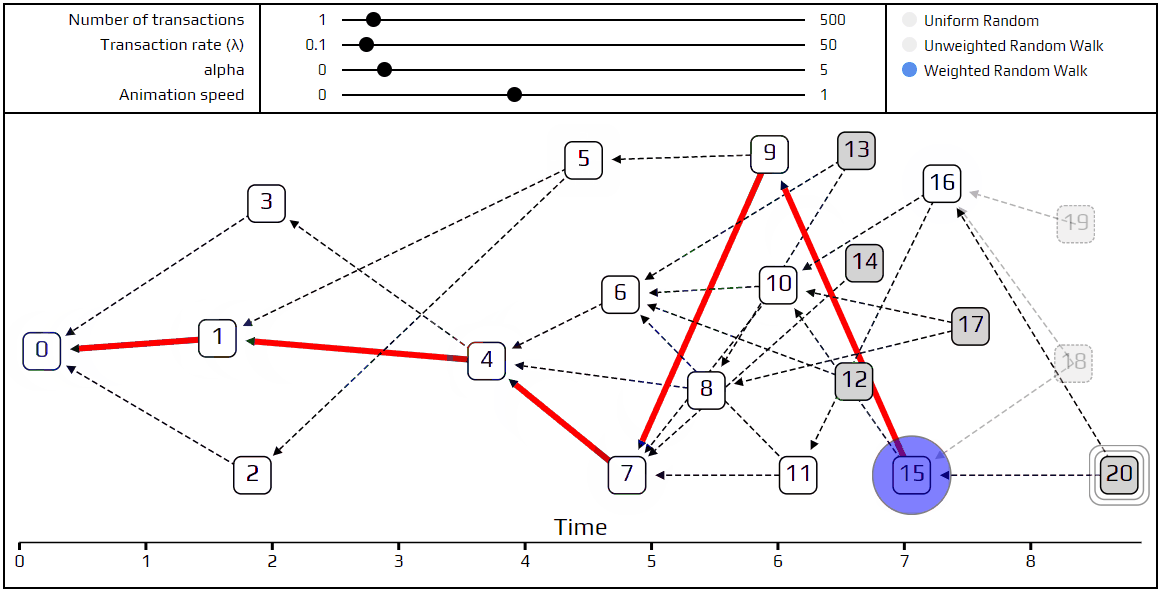
As always, we have a simulation to demonstrate these new ideas. We recommend playing around with the values of α and λ, and seeing what kind of interesting Tangles you can cook up. Next week we will go into more detail about what it means to say that transaction A approves transaction B, and define when a transaction is considered to be confirmed.
Part 1: Introduction to the Tangle
Part 2: transaction rates, latency, and random walks
Part 4: Approvers, balances, and double-spends
Part 5: Consensus, confirmation confidence, and the coordinator
Follow us on our official channels for the latest updates
Discord | Twitter | LinkedIn | Instagram | YouTube


